 |
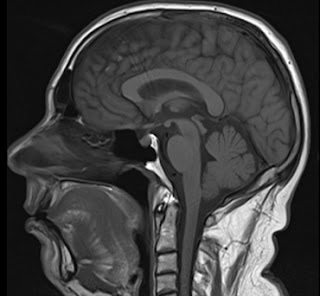
| Old MRI image, not showing my stroke |
If you think you are having a stroke, call 999, get help as soon as possible, please.For more information see stroke.org.uk
But this is my experience.
Misconceptions
I was surprised how much people don't know about a stroke. I ended up writing a long explanation for my family to cover it. One of my daughter's has worked with stroke patients in a care home and was "D'Uh!", but I think it helped the rest understand.
One of the things I found difficult was people asking "how are you feeling now", and "get well soon". A stroke, like most "long term" illnesses, is very different to the average illness. It is not like a cold, or even like a broken leg.
Basically - I feel fine. I actually "felt fine" the whole time - I just could not speak for about 4 hours. Maybe, and not even that much, a little tired, and that is it. I don't feel ill at all.
But also "get well soon" is not really a thing in the same way. The damage is done. The "getting better", in terms of brain cells that recovered from the lack of oxygen, has happened, within the first few hours. Yes, there is some re-learning stuff my brain could do over a longer term, maybe, if I am lucky. In my case I can tell my speech is not quite back to normal, but just the occasional word tripping me up. That may never go away. For worse strokes there may be possible rehab and physiotherapy that can help some recovery over time. But the whole process is very different to the "get well soon" you would apply to someone with a cold.
The usual platitudes for someone that has been ill or injured are not ideal, and even wind me up slightly as it is hard to give the simple answer. Sorry.
Background
I have been doing well. I have managed to lower my weight steadily over the last six months, doing more exercise. I have managed to keep my blood pressure and blood sugar well under control. Ticking all the boxes. No reason to have a stroke.
COVID
I made the mistake of going on a cruise. I did take quite a few precautions, including avoiding a commercial flight, not having to queue up for anything (yes, it was one of those cabins at the top of the ship that gets you a personal escort to the front of queues) and masking up in crowded spaces. Sadly I did go to the bar, and even with a table at the end out of the way and the small group of the same people, one of them got COVID the day before me. The two people on the cruise with me did not. Very unlucky.
But COVID is just like a nasty cold, and over in a week, right?
Wrong!
Yes, the main symptoms, in this case a severe fever and cough, cleared up a lot in 3 or 4 days. I was left with a nagging cough (which happened last time and lasted a few weeks), and a bit tired.
I'd like to thank Mike and Simon for ensuring a supply of pizza, starbucks, and paracetamol turned up at my cabin door.
But on returning from the cruise I realised my blood pressure was unusually high.
Mistake 1: I should have contacted my GP and got something done about it, even if only temporary while the COVID symptoms clear up finally. That said, blood pressure on its own is not what triggers the stroke - it is likely COVID causing blood clots - but the high blood pressure is a risk factor and an clear indication of COVID messing with me still.
Stroke
As seems to be a common thing now with COVID - I then had a stroke. It was 11 days after first COVID symptoms.
It was fortunate that I had reason to go and talk to someone - I managed to leave my glasses in a shop in town and walked back to find them. If not, I would have been sat at home and not had any cause to talk to anyone. When I got there I realised I could not talk properly! My speech was really slurred. The people in the shop did not know me and so did not know that was not my normal speech.
I went home and double checked. I recorded myself and played back. I could smile. I could raise my arms, and legs. But my speech was slurred. Oddly it seemed worse to me when speaking than it did listening to the playback, but even so, the playback was slurred. I have learned that some people cannot tell their speech is slurred, which is interesting - I definitely could.
Given the horror stories about delays with ambulances of late I decided not to wait, and just walk to the minor injuries unit at Nevill Hall. It is 20 minutes or so, but I am pretty confident it was quicker than an ambulance would have been. Obviously in different circumstances I would have either been driven by my wife (she was out) or called 999 for an ambulance. In hindsight, starting to walk, and calling 999 from my mobile, may have been the best of both worlds - though "calling 999" with dysarthria may well have been a problem.
Yay! I learned a new word, dysarthria.
Nevill Hall
The MIU were good. I had to type on my phone to be understood - I did this whilst walking to the unit anyway, so was ready. Fastest triage ever - I did not have time to sit down. I was on a bed, on a drip, CT scan, and then very quickly in ambulance (blue lights!) to The Grange hospital, 20 minutes away. They got me on aspirin pretty quickly.
The Grange
Being in hospital sucks, I know. First night I was in resus in the emergency department on a monitor and there is no way to get any sleep. Then was transferred in morning via "Majors" and "Assessment" before going on to the actual stroke ward.
I spent three nights in hospital, bored silly. I had a book, and my phone, but still bored. The ward was good though, a shower, reasonable food, comfortable bed. But 3 hourly obs (blood pressure, pulse ox, temp, pupil response) makes a good night's sleep impossible.
The stroke tests get very tedious...
- Smile
- Stick tongue out and move left/right
- Raise arms
- Raise legs
- Grip
- Push (arms and legs)
- Pull (arms and legs)
- Where are you?
- What month is it? (yes, even at 1am on 1st October, I passed)
- Who's the King?
Now, I know they are important test, and I know the staff are doing their job, honest.
The real problem is a stroke is very different to a lot of other illnesses. At this point, I was not "ill" any more. I felt fine. My speech was 99% back to normal after only a few hours on Friday. Being in hospital when not actually ill is extra frustrating.
But the staff were great, and have my thanks.
Some minor niggles
There is equipment for monitoring patents. It does blood pressure, ECG if needed, pulse ox. On Friday I was plumbed in to it. But after that it was used for regular obs, so blood pressure cuff and pulse ox sensor. The problem is that they left it switched on. This means a beep every 5 seconds to warn that it is not "connected" to the patient any more. It is a matter of a button press to shut it up.
There are two problems with this!
- The noise. Four of these on the ward all doing a beep every 5 seconds all the time, all out of phase. This is not conducive to patient care and getting rest.
- The more serious issue - these things beep for a reason. They are alerting that something is wrong (in this case, simply that they are disconnected). By ignoring the beeps, becoming deaf to them, they lose any usefulness - the beeps can no longer be effectively used to actually warn that something is wrong any more. It has to be bad practice to ever leave any such equipment generating an ongoing warning beep.
There are some cases where a beep is not a warning as such, such as the heat beat beeps for the ECG when in ED, where the beeps can allow the attending nurse to instantly hear even subtle problems. But on the ward there was nobody on ECG, so not the issue.
I did manage to get them turned off, but had to ask on several occasions, and the stock answer is "we have to monitor some patients", and I have to explain that I understand, but these are from machines that are not monitoring patients!
The other obvious niggle is that I was only really there for three days, not for observation, but because of the time it takes to get an MRI, Doppler scan, and see occupational health and speech therapist. That could have all been done after 24 hours, but a lot of stuff is not done at weekends. At the end of the day, that is just how it is.
Oh, and being supervised taking my regular meds felt like I was some sort of naughty schoolboy! They also struggled with the notion that I set my own insulin dose, and adjusted it because being in hospital was different (led to a hypo in the night, so lowering the dose).
Stroke doctor
The stroke doctor basically explained it was a mini stroke. He did the checks again, and a number of perceptual checks. He explained that I would be on aspirin for 3 weeks, and blood thinners permanently, and some slight changes to other meds.
However there were a couple of oddities. He was a stroke specialist, but still, I was surprised.
- He commented how my HbA1c (overall blood sugar measure for diabetics) was really good, and maybe I should not be on meds/insulin for diabetes. This makes no sense to me (or my GP) as the very reason my HbA1c is good is because I am on the meds and they are working!
- He asked about migraines, and I explained I get an aura only, one side or the other. He said "so one eye or the other". I corrected him that it was one side of my vision, or the other, and not one eye or the other. He continued with "one eye or the other" so I gave up.
Followup information
This was another surprise. I got following information on (a) not driving for a month, and (b) speech therapy. But I got absolutely nothing on strokes. No "what is a stroke? what causes a stroke? What risk factors can you mitigate in future? Why do you have blood thinners?" etc. I can research these myself, but why no information pack? I bet a lot of patients leave confused about what has happened and what they should do about it.
Work
Obviously I work - I run an ISP. But my management team are very good, so have no problem with my trying to rest for a few weeks, or longer if I was to be seriously ill. I am obviously keeping an eye on things as "taking a rest" is not quite the same as "doing nothing" which would wind me up even more.
COVID recovery
Right now, my main concern is the COVID symptoms - the cough and high blood pressure. Especially the high blood pressure. I have been working with my GP - higher dose of some meds while it is a problem, and that seems to be working now. Oh, and saying "stroke" to a GP receptionist seems to be a magic spell for getting an immediate call back from a doctor.
People need to realise COVID is still very common and still very serious. Whilst my case was "minor", a stroke can be a serious long term impact on someone's life, and the lives of their family, for the rest of their life. In some ways it can be worse than COVID just killing people off (and I say that as someone that watched my father die of COVID just a year ago).
It is not just a cold. Please take it seriously.
 Ordering PCBs and assembly is fun :-)
Ordering PCBs and assembly is fun :-)